S3 Parquet Integrationを使ってAuroraからTreasure Dataに定期インポートしてみた
こんにちは。システム開発部のsonohaです。ニフティ温泉のWEBサイトの開発全般を担当しています。
今回は、2023年10月現在にTreasure Dataでベータ版として提供されているS3 Parquet Integrationを使い、Amazon Aurora MySQLからTreasure Dataへ定期的にデータをインポートしてみたので、その方法をご紹介したいと思います。
目次
背景
当社ではデータウェアハウス基盤としてTreasure Dataを採用しています。
普段、業務データの一部をTreasure Dataにインポートし、データの分析や可視化を行っています。
これまで、Amazon S3上のJSON, CSV, TSVファイルをTreasure Dataへインポートする手段として、S3 Export Integrationが提供されてきました。
例えばAmazon DynamoDBのデータをS3へエクスポートするとJSONファイルとして出力されるため、この機能は大変重宝しています。
一方で、Amazon Aurora DBクラスターデータをS3へエクスポートするとApache Parquet形式で圧縮されるため、先のS3 Export Integrationではインポートできないという課題がありました。
これを解決するのが、今回ご紹介するS3 Parquet Integrationとなります。
利用方法
今回はLambdaを利用して、自動的にAuroraのデータを定期エクスポートしTreasure Dataへインポートします。
簡単な構成図を以外に示します。
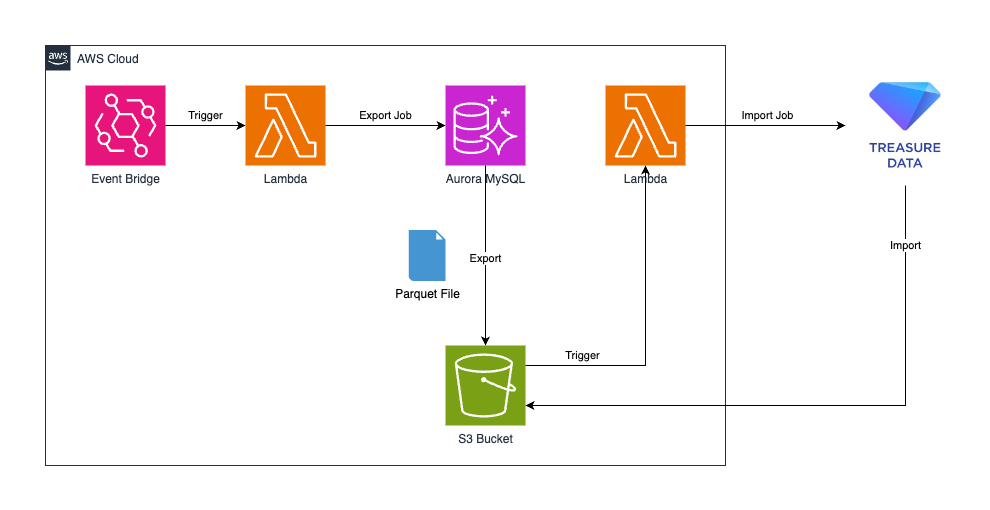
大まかな手順は次の通りです。
- 機能を有効化する
- Auroraエクスポートをトリガーする
- S3バケットへのTreasure Dataからのアクセスを許可する
- Treasure Dataにインポートジョブを発行する
機能を有効化する
S3 Parquet Integrationは2023年10月現在ベータ版機能であり、利用開始には申請が必要です。Treasure DataのCS担当者に連絡して機能を有効化いただきましょう。
申請フォーマットは特に無いようなので、何にどのように利用したいのかを併せてご連絡いただくと、その後の手続がスムーズかと思います。
Treasure Dataコンソール上に次のようなメニューが表示されれば準備完了です。

Auroraエクスポートをトリガーする
AWS SDK for JavaScript V3を用いて、次のようなシンプルなコードを持つLambda関数を作成します。
予めエクスポート先のS3バケットを作成しておき、バケット名をLambdaの環境変数に指定してください。
const { RDS } = require("@aws-sdk/client-rds");
const aurora = new RDS();
const clusterArn = process.env.DBCLUSTER_ARN;
const iamRoleArn = process.env.IAM_ROLE_ARN;
const kmsKeyId = process.env.KMS_KEY_ID;
const destinationS3 = process.env.EXPORT_DESTINATION_S3_BUCKET_NAME;
const table = process.env.TABLE_NAME;
exports.handler = async (event, context, callback) => {
try {
await aurora.startExportTask({
ExportTaskIdentifier: `task-${Date.now()}`,
IamRoleArn: iamRoleArn,
KmsKeyId: kmsKeyId,
S3BucketName: destinationS3,
S3Prefix: `parquet/${Date.now()}`,
SourceArn: clusterArn,
ExportOnly: [table],
});
} catch (err) {
console.error(err);
}
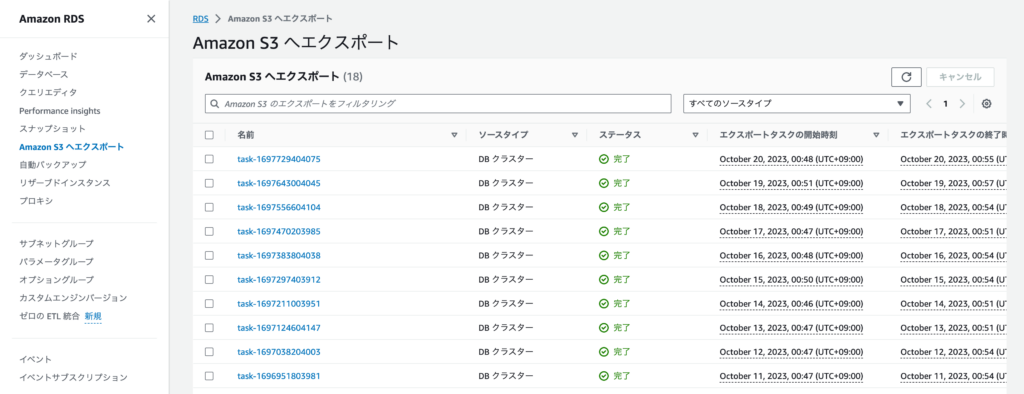
};試しにテスト実行をしてみると、AWSコンソールからRDSサービスの「Amazon S3 へエクスポート」を確認すると、エクスポートジョブが発行されていることを確認できます。
直近のDBスナップショットを復元してエクスポートする仕組みなので、データ量などにもよりますがジョブが発行されてからエクスポート実行までに5〜10分ほどのタイムラグがあることに注意してください。
テスト実行を確認できたら、LambdaのトリガーにEvent Bridgeを設定しましょう。cron式で定期実行の間隔を定義できます。
これにて定期エクスポートの設定は完了です。
S3バケットへのTreasure Dataからのアクセスを許可する
S3バケットに置かれたParquetファイルをTreasure Dataへインポートするには、Treasure DataからのS3バケットへのアクセスを許可する必要があります。
S3 Parquet Integrationのドキュメントに従うと、S3のバケットポリシーでTreasure DataコンソールのIPアドレスセットからのアクセスを許可するのが最も簡単な方法です。
次のようなバケットポリシーを追加します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": "*",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<<S3バケット名>>",
"arn:aws:s3:::<<S3バケット名>>/*"
],
"Condition": {
"IpAddress": {
"aws:SourceIp": [
"<<Treasure DataコンソールのIPアドレス>>",
"<<Treasure DataコンソールのIPアドレス>>",
"<<Treasure DataコンソールのIPアドレス>>",
...,
"<<Treasure DataコンソールのIPアドレス>>"
]
}
}
}
]
}具体的なTreasure DataコンソールのIPアドレスセットは、CS担当者にご確認ください。
また、Treasure Dataからのアクセス許可は、最低限の読み取りアクションのみにしておきます。
Treasure Dataにインポートジョブを発行する
次に、Pythonのtd_clientを用いてインポートジョブを発行するLambda関数を作成します。
次のような関数を用意します。
import botocore.exceptions
import boto3
import re
import os
import base64
import tdclient
ACCESS_KEY = os.environ['S3_ACCESS_KEY']
SECRET_KEY_ARN = os.environ['S3_SECRET_KEY_ARN']
S3_BUCKET_NAME = os.environ['S3_BUCKET_NAME']
SUCCESS_FILE_NAME = '_SUCCESS'
TD_DB_NAME = os.environ['TD_DB_NAME']
TD_TABLE_NAME = os.environ['TD_TABLE_NAME']
def lambda_handler(event, context):
file_key = event['Records'][0]['s3']['object']['key']
if not file_key.endswith(SUCCESS_FILE_NAME):
return
data_file_prefix = get_data_file_prefix(file_key)
secret_key = get_secret(SECRET_KEY_ARN)
config = {
'config':{
'in': {
'type': 's3_parquet',
'access_key_id': ACCESS_KEY,
'secret_access_key': secret_key,
'bucket': S3_BUCKET_NAME,
'path_prefix': data_file_prefix,
'path_match_pattern': '\.parquet$',
},
'filters': [
{
'from_value': {'mode': 'upload_time'},
'to_column': {'name': 'time'},
'type': 'add_time'
}
],
'out': {
'mode': 'replace'
}
}
}
try:
with tdclient.Client() as td:
job_id = td.api.connector_issue(TD_DB_NAME, TD_TABLE_NAME, config)
print(f'TD Import Job ID: {job_id}')
except Exception as error:
raise error
def get_data_file_prefix(file_key):
try:
return re.findall('(^.+/)' + SUCCESS_FILE_NAME + '$', file_key)[0]
except Exception as e:
return None
def get_secret(id):
client = boto3.session.Session().client(service_name='secretsmanager', region_name='ap-northeast-1')
try:
resp = client.get_secret_value(SecretId=id)
if 'SecretString' in resp:
print("Found Secret String")
return resp['SecretString']
else:
print("Found Binary Secret")
return base64.b64decode(resp['SecretBinary'])
except botocore.exceptions.ClientError as err:
return NoneTreasure Dataのドキュメントにはこの利用方法は記載されていませんが、Treasure DataのCLIツールであるToolbeltと同じように扱うことができました。
config変数に設定している内容は次の通りです。
| パラメータ名 | 必須 | 説明 |
|---|---|---|
| type | ○ | インポートタイプを指定します。 今回は s3_parquetで固定です。 |
| access_key_id | ○ | S3バケットのアクセスキーを指定します。 TDがS3バケットへリクエストする際に使われます。 |
| secret_access_key | ○ | S3バケットのシークレットアクセスキーを指定します。 TDがS3バケットへリクエストする際に使われます。 |
| bucket | ○ | インポート対象のバケット名を指定します。 |
| path_prefix | × | S3バケット内のプレフィックスを指定し、インポート対象とするファイルを絞り込めます。 |
| path_match_pattern | × | 正規表現で、インポート対象とするファイル名を絞り込めます。 |
最後に、作成したLambda関数のトリガーに、Auroraのエクスポート先であるS3バケットのObjectCreatedイベントを指定します。これにより、対象のS3バケットにParquetファイルが置かれると自動的に関数が実行され、全データがTreasure Dataにインポートされます。
エクスポート対象データが多い場合には複数のParquetファイルが生成されるようですが、私の環境では正常に全件インポートされることを確認できました。
最後に、作成したLambda関数のトリガーに、Auroraのエクスポート先であるS3バケットのObjectCreatedイベントを指定し、サフィックスフィルタに_SUCCESSを設定しておきます。これにより、対象のS3バケットに_SUCCESSファイルが置かれると自動的に関数が実行され、一緒に置かれている全ParquetファイルがTreasure Dataにインポートされます。
2023/11/08
当初の実装方式の場合、各Parquetファイルの配置毎にLambdaが起動し、Treasure Dataへのデータインポート数が肥大化してしまうため、記事の内容および参考コードを修正しました。
改善点
Auroraのエクスポートがデータ全件であるため、Treasure Dataへのインポート戦略はデータすべてを洗い替えるreplaceを採用しています。
エクスポート対象のデータが大規模である場合には、実行時間やコスト面で困るかもしれません。
今回は試していませんが、replace_on_new_data戦略を指定することでインポート時のパフォーマンスが改善する可能性があります。
また、TD Workflowにはデータの差分だけをインポートできるIncremental Data Import機能が備わっています。
現時点ではS3 Parquet Integrationは差分インポートの対象外の想定ですが、将来的に対象となった場合にはこれを活用することで実行時間やコストを最適化できる可能性があります。
注意事項
繰り返しになりますが、S3 Parquet Integrationは2023年10月時点でベータ版の機能になります。
事前の告知なく仕様変更が入る可能性もありますので、ご利用の際は自己責任でお願いいたします。
(ニフティ温泉では、まずは3ヶ月間だけの限定的な利用に留めています。)
まとめ
今回はTreasure DataのS3 Parquet Integrationを用いて、Amazon AuroraのデータをS3経由でTreasure Dataにインポートしていきました。
ポイントは次の通りです。
- 今までできなかったParquetファイルのインポートができるようになった。
- ベータ版機能なので、利用開始には申請とアクセス許可が必要。
- Lambdaで実行可能なので、定期的な自動実行も簡単に実現できる。
- ベータ版機能なので、急な仕様変更には要注意。
以上、ご参考になりましたら幸いです。
最後までお読みいただきありがとうございました!
掲載内容は、記事執筆時点の情報をもとにしています。